
Dette er femte del i serien “Hvad er AI?”. Formålet med serien er, at komme med en uddybning af nogle af de centrale begreber indenfor kunstig intelligens og den er altså ikke tænkt til dig, der allerede ved alt om AI. Du kan læse fjerde del her.
TL;DR: Fire hovedpointer
- Deep learning er en avanceret form for maskinlæring, der bruger dybe neurale netværk til at lære komplekse mønstre fra store datasæt, hvilket gør det effektivt til opgaver som billed- og talegenkendelse.
- Historien om deep learning strækker sig over flere årtier, med rødder i 1940’erne, men fik først betydelig opmærksomhed i 1980’erne med introduktionen af backpropagation og senere med gennembrud som AlexNet i 2012.
- Træning af dybe neurale netværk indebærer flere trin, herunder forward propagation, fejlberegning, backpropagation og iterativ optimering, som kræver store mængder data og beregningskraft.
- Deep learning anvendes bredt i mange områder, herunder ansigtsgenkendelse, talegenkendelse, naturlig sprogbehandling og selvkørende biler, hvor det har revolutioneret måden, disse teknologier fungerer på.
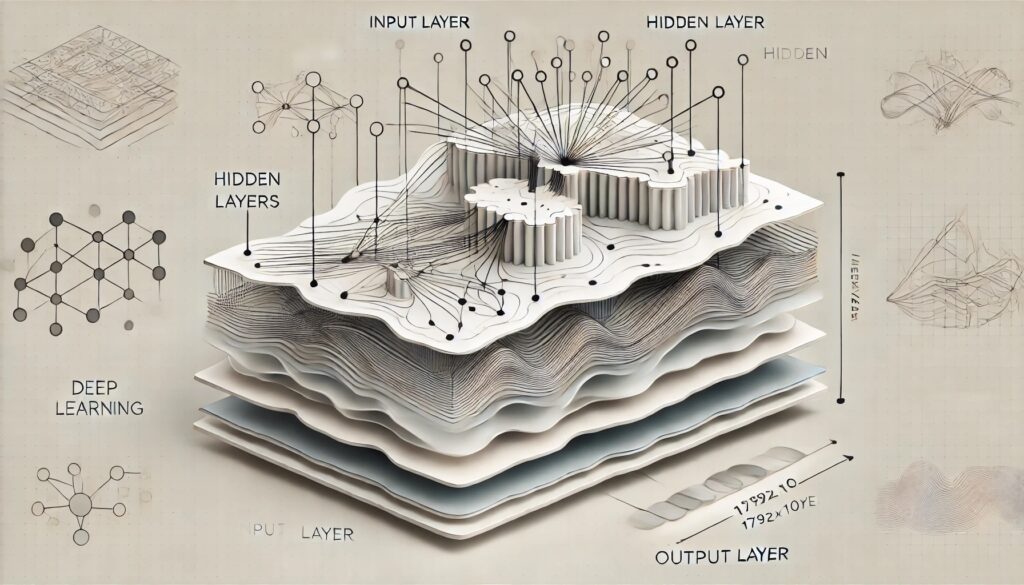
Deep learning er en underkategori af maskinlæring og en central teknologi inden for kunstig intelligens (AI). Det adskiller sig fra traditionel maskinlæring ved at være i stand til at lære fra store mængder komplekse data ved hjælp af dybe neurale netværk, som består af mange lag af kunstige neuroner. Disse netværk efterligner den menneskelige hjernes måde at behandle information på, og de har muliggjort store fremskridt inden for områder som billedgenkendelse, talegenkendelse, og naturlig sprogbehandling.
Hvad er Deep Learning?
Deep learning er en avanceret form for maskinlæring, der udnytter dybe neurale netværk til at lære komplekse mønstre i data. Du kan læse mere om maskinlæring og neurale netværk i de tidligere afsnit af denne serie. I modsætning til traditionelle neurale netværk, der typisk består af få lag, består deep learning-modeller af mange lag – ofte kaldet skjulte lag – der gør det muligt for netværket at udføre gradvise transformationer af data, fra rå input til sofistikerede repræsentationer.
I deep learning kan disse flere lag automatisere processen med funktionsekstraktion, hvor hvert lag i netværket lærer at identificere specifikke træk eller mønstre. For eksempel, i billedgenkendelse vil de første lag typisk lære at genkende simple kanter og former, mens de dybere lag kombinerer disse simple træk for at genkende komplekse objekter som ansigter eller biler.
Den dybe arkitektur gør det muligt for netværket at lære på flere niveauer af abstraktion, hvilket gør deep learning ekstremt effektiv til opgaver, hvor traditionelle metoder ville kræve omfattende manuel funktionsekstraktion eller simpelthen ikke kunne levere den nødvendige nøjagtighed.
Ved at anvende algoritmer som backpropagation og optimeringsteknikker som gradient descent kan deep learning-modeller effektivt trænes på store datasæt, hvilket gør dem velegnede til opgaver, hvor der er rigelig tilgængelig data, såsom billede- og talegenkendelse, naturlig sprogbehandling, og selvkørende køretøjer.
Deep learning er ikke en ny ide
Deep learning har sine rødder dybt forankret i udviklingen af kunstig intelligens (AI) og maskinlæring, og dets historie strækker sig over flere årtier. Mens idéerne bag dybe neurale netværk har eksisteret i årtier, er det først i de seneste årtier, at deep learning er blevet praktisk anvendeligt og bredt anerkendt.
Kort fortalt offentliggjorde Warren McCulloch og Walter Pitts i 1943 en banebrydende artikel, hvor de beskrev en matematisk model af en kunstig neuron, der kunne udføre simple logiske operationer. Dette var det første forsøg på at efterligne hjerneaktivitet gennem en matematisk model, og det lagde grundlaget for udviklingen af neurale netværk.
På den baggrund kunne Frank Rosenblatt i 1948 udvikle perceptronen, en simpel model af en enkeltlagsneuron, som kunne klassificere data i to kategorier. Perceptronen var inspireret af den biologiske neuron og blev betragtet som et af de første neurale netværk. Modellen var dog begrænset til lineært separerbare problemer, hvilket betyder, at den ikke kunne håndtere mere komplekse, ikke-lineære opgaver.
Ideen vandt dog ikke indpas og da Marvin Minsky og Seymour Papert i 1969 udgav bogen “Perceptrons”, hvor de kritiserede begrænsningerne ved enkeltlags perceptroner, især deres manglende evne til at løse ikke-lineære problemer lagde det ideen i graven. Kritikken førte til en periode med stagnation i forskningen i neurale netværk, ofte omtalt som AI’s første “vinter”. Forskere blev mere fokuserede på symbolsk AI, som syntes mere lovende på det tidspunkt.
I 1986 genopstod interessen for neurale netværk, da Geoffrey Hinton, David Rumelhart, og Ronald J. Williams genintroducerede og populariserede algoritmen for backpropagation. Backpropagation gjorde det muligt at træne dybere netværk ved at justere vægte i flere lag baseret på fejlens gradient. Dette gennembrud åbnede døren for anvendelse af dybere neurale netværk til mere komplekse opgaver.
Yann LeCun, der i dag leder Meta’s AI-afdeling, anvendte i 1989 backpropagation til at udvikle Convolutional Neural Networks (CNNs), som blev brugt til håndskriftgenkendelse, herunder postnummergenkendelse på breve. Dette var et af de første eksempler på dybe netværk, der blev brugt i kommercielle applikationer.
I løbet af 1990’erne blev neurale netværk mere udbredt i kommercielle produkter, såsom håndskriftgenkendelse i banksystemer og optisk tegngenkendelse (OCR). Teknologien var dog stadig begrænset af datidens computerkraft og manglen på store datasæt.
Geoffrey Hinton introducerede i 2006 begrebet “deep learning” og viste, hvordan dybe neurale netværk kunne trænes effektivt ved hjælp af pre-træning med metoder som Restricted Boltzmann Machines (RBMs). Dette førte til en fornyet interesse for dybe netværk, da det blev muligt at træne dybe lag én ad gangen, før de blev finjusteret ved hjælp af backpropagation.
Forbedringer i Computerkraft og Algoritmer: Fremkomsten af kraftfulde grafikkort (GPUs) revolutionerede i løbet af 00’erne træningen af dybe neurale netværk, da disse kort kunne udføre de parallelle beregninger, der kræves for at træne store netværk meget hurtigere end traditionelle CPU’er. Samtidig blev teknikker som dropout (introduceret af Geoffrey Hinton i 2012) udviklet for at forhindre overfitting i dybe netværk.
Det store gennembrud for deep learning kom i 2012, da Alex Krizhevsky, Ilya Sutskever, og Geoffrey Hinton vandt ImageNet-konkurrencen med AlexNet, et dybt CNN, der satte nye standarder for billedgenkendelse. AlexNet demonstrerede overlegen præcision og blev en milepæl, der markerede deep learnings indtog i mainstream-forskning og -industri.
Ian Goodfellow introducerede i 2014 Generative Adversarial Networks (GAN’s), en ny metode inden for deep learning, der gør det muligt at generere nye data, der ligner eksisterende data. GANs har siden været brugt til alt fra kunstskabelse til dataforstærkning.
Transformer-modellen: I 2017 introducerede transformer-arkitekturen, der revolutionerede naturlig sprogbehandling (NLP) ved at forbedre, hvordan modeller kunne håndtere sekventielle data som tekst. Denne arkitektur ligger til grund for moderne sprogmodeller som BERT, GPT-3 og GPT-4.
– 2018 og frem: BERT og GPT: Sprogmodeller som BERT (Bidirectional Encoder Representations from Transformers) og GPT (Generative Pre-trained Transformer) har fra 2018 og frem demonstreret deep learnings evne til at forstå og generere naturligt sprog med en hidtil uset nøjagtighed og sammenhæng. GPT-3, med sine 175 milliarder parametre, markerede en ny æra for AI med dens evne til at skrive komplekse tekster, programmere, og meget mere.
Deep learning er nu en integreret del af mange moderne AI-systemer, der driver alt fra sprogmodeller og billedgenkendelse til autonome køretøjer og medicinsk diagnostik. Forskning inden for deep learning fortsætter med at fokusere på at forbedre modellernes præcision, effektivitet, og forklarbarhed. Nye metoder som transfer learning, reinforcement learning, og integrering af kvante computing lover at udvide mulighederne endnu mere.
Hvordan fungerer deep learning?
Deep learning fungerer ved at bruge flere lag af neuroner, hvor hver neuron modtager input, udfører en beregning, og sender output videre til næste lag. Hvert lag i et dybt neuralt netværk behandler inputtet på et højere niveau af abstraktion. For eksempel, i billedgenkendelse kan de første lag i netværket opdage kanter i billeder, de næste lag kan opdage former, og de sidste lag kan genkende hele objekter som biler eller ansigter. Du kan læse en længere gennemgang af hvordan neurale netværk fungerer i den fjerde del i denne serie ”Hvad er AI: Neurale netværk”.
Træning af Dybe Neurale Netværk
Træning af dybe neurale netværk er en kompleks proces, der involverer justering af vægte og bias for at minimere fejl i netværkets forudsigelser. Denne proces kræver store mængder data og betydelig beregningskraft. De vigtigste trin i træningsprocessen er:
1. Forward Propagation: Dataene føres gennem netværket fra inputlaget til outputlaget. Hvert lag i netværket anvender vægte på inputtet og sender det til næste lag.
2. Fejlberegning: Når dataene når outputlaget, sammenlignes netværkets forudsigelse med det faktiske resultat. Forskellen mellem de to kaldes “fejlen” eller “tabet.”
3. Backpropagation: Fejlen spredes bagud gennem netværket, og vægtene justeres for at reducere fejlen i efterfølgende iterationer. Dette sker gennem algoritmer som gradient descent, som justerer vægtene i små trin i den retning, der mindsker fejlen mest effektivt.
4. Iterativ Optimering: Træningsprocessen gentages mange gange, ofte i tusindvis af iterationer, indtil netværket er tilstrækkeligt trænet til at generalisere til nye data.
Anvendelser af Deep Learning
Deep learning anvendes i mange forskellige områder og har revolutioneret adskillige felter.
Deep learning anvendes i ansigtsgenkendelse, medicinsk billedanalyse, og klassifikation af billeder. For eksempel bruges Convolutional Neural Networks (CNNs) til at analysere billeder ved at lære mønstre som kanter, teksturer og former.
Stemmeteknologi som Siri, Alexa og Google Assistant bruger dybe neurale netværk til at transkribere og forstå talt sprog. Recurrent Neural Networks (RNNs) og Long Short-Term Memory networks (LSTMs) er ofte brugt til at håndtere sekventielle data som lyd.
– Naturlig Sprogbehandling (NLP): Deep learning-modeller som transformer-modeller anvendes hjælp af natulig sprogbehandling (Natual Language Processing – NLP), der gør maskinlærings modeller i stand til at forstå menneskeligt sprog, til oversættelse, sentimentanalyse, og tekstgenerering. Disse modeller har muliggjort fremskridt i sprogmodeller som GPT-3 og GPT-4.
Dybe netværk bruges til at analysere omverdenen gennem kameraer og andre sensorer, hvilket gør det muligt for biler at navigere selvstændigt.
 Share
Share{kind=link}